문제 유형
1번문제 기본문제
2/3/4 는 분류문제
sigmoid/ softmax둘 중 하나
checkpoint
callback = [checkpoint]
저장을 한 후 자동으로
best epoch의 w 값을 실어주기
매 epoch 마다 loss가 더 낮게 나오면 checkpoint에 저장된다
가장 마지막 코드
model.load_weights(checkpoint_path)
2번은 3가지 문제 중에 한가지 랜덤하게 나옴 (2가지 유형)
1) 이미지 분류 2개 - mnist 손글씨분류 / fashion mnist
2) 정형데이터 - iris 꽃 분류문제
이미지 rescale
픽셀들을 하나씩 까서 보면 0~255 사이의 값을 가지고 있다.
1. 모든 픽셀 값이 0~1 사이의 값을 가지도록 하자 = Normalization
x_train = x_train / 255.0
x_valid = x_valid / 255.0
y는 class값임 분류 값이므로 255로 나누어서는 안된다.
이미지 데이터인 x 에 대해서만 255로 나누어 rescale을 해준다.
Normalization을 해야하는 이유?
- 데이터 분산 값을 줄여줌으로서 원하는 목표 loss 까지 수렴이 더 빨리 된다.
2. OneHot Encoding
빨강 1
노랑 2
파랑 3
>>>>>>>>>>>>>
빨강 (1, 0, 0)
노랑 (0, 1, 0)
파랑 (0, 0, 1)
y.head() / y_train[0] 등과 같이 y값을 살짝 찍어보면, onehot 인코딩 여부를 확인 할 수 있다.
| onehot 인코딩 된 Y 값 | onehot 인코딩 안 된 Y값 |
| [0,0,0,1,0] | 3 |
| [0,1,0,0,0] | 1 |
| [0,0,0,0,1] | 4 |
| [1,0,0,0,0] | 5 |
Onehot 인코딩 하는 방법
print(tf.one_hot(y_train[0], 10))print(tf.one_hot(y_train[0], 10))
3. 선형 / 비선형 번갈아가면서 사용하기
Dense 선형
Relu 비선형
tf.keras.layers.Dense(512)
tf.keras.layers.Relu(512)
tf.keras.layers.Dense(512, activation = 'relu') 와 같이 표현 가능
def relu(x):
return np.maximum(x, 0)
x = np.linspace(-10, 10)
y = relu(x)
plt.figure(figsize=(10, 7))
plt.plot(x, y)
plt.title('ReLU activation function')
plt.show()
4. 마지막 Dense
분류해야할 클래스의 갯수와 맞춰서 써주기
tf.keras.layers.Dense(1, activation = 'sigmoid')
tf.keras.layers.Dense(10, activation= 'softmax')
5. 컴파일 주의사항
softmax => loss = 'sparse_categorical_crossentropy')
sigmoid => loss = 'binary_crossentropy'
***********************************************************************
이진분류 : 둘 중 하나 (ex) 개 / 고양이, 나비 / 벌 )
방법1)
Dense(1, activation = 'sigmoid')
loss = 'binary_crossentropy'
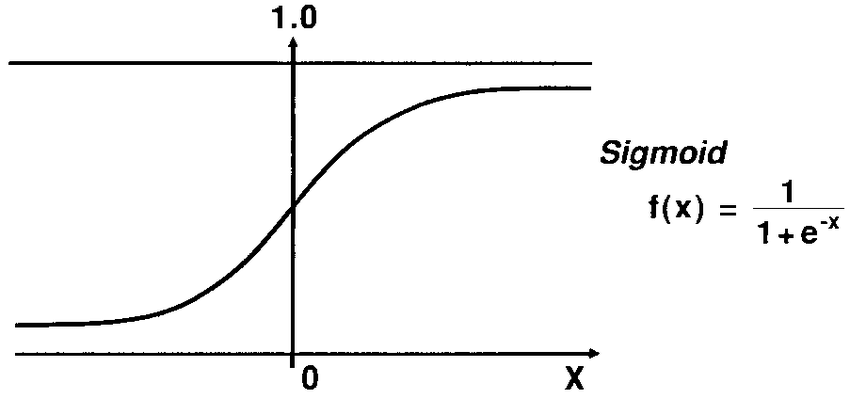
sigmoid 함수는 x에 어떤 값을 넣든지 y는 0과 1 사이의 값이 나온다.
이 함수가 이진 분류에서 사용된다면, y값이 0.5 를 기준으로 개/고양이 분류를 한다.
def sigmoid(z):
return 1/(1+np.exp(-z))
plt.figure(figsize=(10, 7))
x = np.arange(-10, 10)
y = sigmoid(x)
plt.plot(x, y)
plt.show()
방법2)
Dense(2, activation = 'softmax')
loss = 'categorical_crossentropy' (y값이 onehot 인코딩 되어있을 때)
또는
loss = 'sparse_categorical_crossentropy' (y값이 onehot 인코딩 안되어 있을 때)
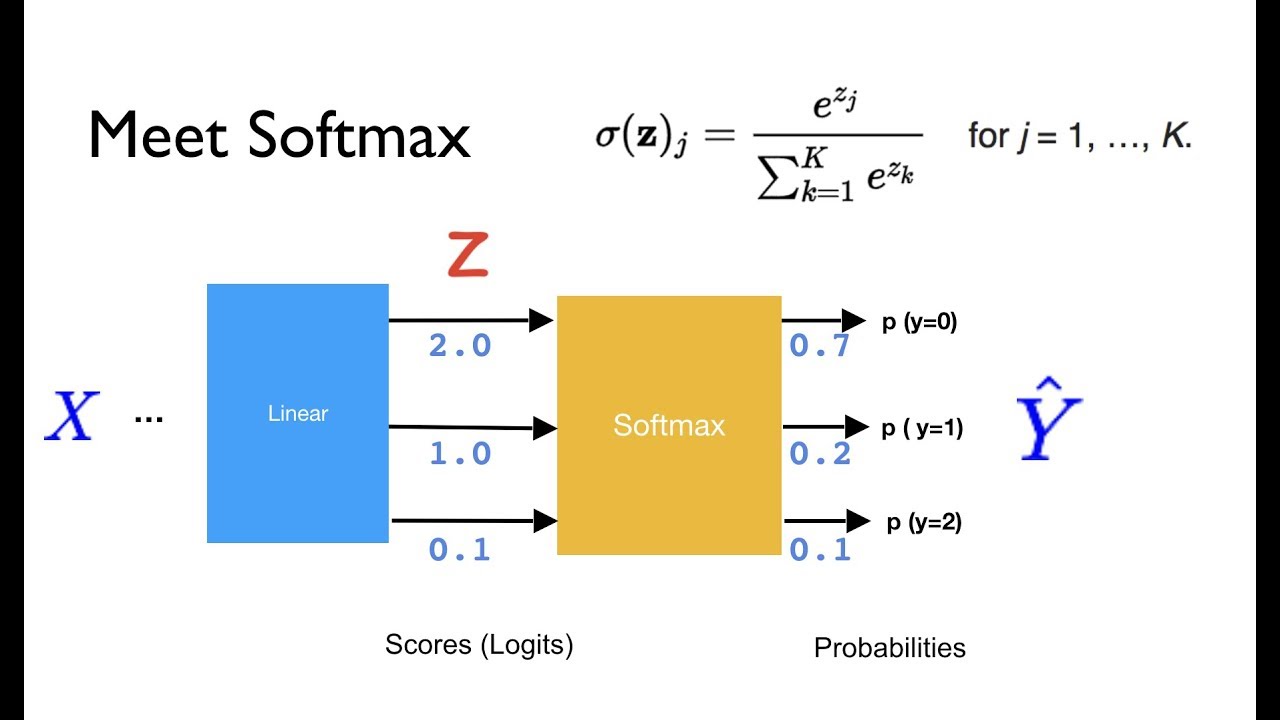
각각의 뉴런이 될 확률을 구해서 가장 큰 값을 가진 뉴런으로 분류
A가 될 확률 : 0.7
B가 될 확률 : 0.2
C가 될 확률 : 0.1
--> A로 분류
import numpy as np
a = np.random.uniform(low=0.0, high=10.0, size=3)
def softmax(a) :
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
y = softmax(a)
print('Class 별 확률 값 출력')
print('===' * 10)
for i in range(3):
print('Class {} 의 확률: {:.3f}'.format(i, y[i]))
print('===' * 10)
print('Class 별 확률 값의 합: {:.1f}'.format(y.sum()))Flatten이란?
- 고차원을 1D로 변환하여 Dense Layer에 전달해 주기 위하여 사용합니다.
- 28 X 28 의 2D로 되어 있는 이미지를 784로 1D로 펼쳐 주는 작업입니다.
이미지는 2차원 데이터(2D)
2D데이터는 Dense Layer에 못들어간다.
2차원 데이터를 1차원으로 변환해주어야 함
5. Model 만들기
model 정의 할 때 input_shape 잡는 법
input 으로 들어가는 x_train의 shape를 확인하면 된다. 해당 결과를 그대로 사용하면 된다 (28,28)
x_train[0].shapemodel = Sequential([
# Flatten으로 shape 펼치기
Flatten(input_shape=(28, 28)),
# Dense Layer
Dense(1024, activation='relu'),
Dense(512, activation='relu'),
Dense(256, activation='relu'),
Dense(128, activation='relu'),
Dense(64, activation='relu'),
# Classification을 위한 Softmax
Dense(10, activation='softmax'),
])Dense 노드를 2의 제곱수로 잡는 이유? : GPU의 병렬처리를 할때 2의 제곱수가 좀 더 학습이 빠름
Dense 노드수가 줄어들게 쌓는 이유? : 논문 등에서 자주 사용되는 경향임. 가이드라인과 같은 역할. 상관없음.
6. Compile
metrics 에 accuracy 담기
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc'])loss = 'categorical_crossentropy'(잘못된 loss 함수)를 사용한다면, accuracy가 안올라감, 학습이 안되는 것
7. ModelCheckpoint: 체크포인트 생성
val_loss 기준으로 epoch 마다 최적의 모델을 저장하기 위하여, ModelCheckpoint를 만듭니다.
- checkpoint_path는 모델이 저장될 파일 명을 설정합니다.
- ModelCheckpoint을 선언하고, 적절한 옵션 값을 지정합니다.
checkpoint_path = "my_checkpoint.ckpt"
checkpoint = ModelCheckpoint(filepath=checkpoint_path,
save_weights_only=True,
save_best_only=True,
monitor='val_loss',
verbose=1)
8. 학습
- validation_data를 반드시 지정합니다.
- epochs을 적절하게 지정합니다. :
- callbacks에 바로 위에서 만든 checkpoint를 지정합니다.
epoch은 감소하다가 다시 늘어나는 지점까지 충분히 주어야한다.
history = model.fit(x_train, y_train,
validation_data=(x_valid, y_valid),
epochs=20,
callbacks=[checkpoint],
)
'AI' 카테고리의 다른 글
| [Utils] 구글 코랩 사용하기 (Google Colaboratory) (0) | 2022.01.07 |
|---|---|
| [Tensorflow 자격증 공부] 선형함수와 오차 (0) | 2022.01.06 |
| [Tensorflow 자격증 공부] Fully Connected Layer (Dense Layer) (0) | 2022.01.04 |
| [AI] 머신러닝을 위한 데이터 준비 (0) | 2022.01.04 |
| [AI] 머신러닝의 개념과 요소 (0) | 2022.01.04 |


