ㅇ 데이터과학의 목표 : 의사결정지원, 수익화(수익창출)
ㅇ 머신러닝의 목표 : 예측과 패턴분석
ㅇ 전체적인 머신러닝 업무 프로세스
1) 문제파악 및 문제정의
2) 데이터 준비
3) 모델구축 & 평가
4) 결과 공유
5) 모니터링
------------------------------------------------------
1. 문제파악 및 문제정의
[세부프로세스]
비즈니스문제파악 - 머신러닝 문제로 전환 - 머신러닝 도입 가능성/필요성 검토 - 효과검증 설계
1) 비즈니스문제파악 = 문제정의(Define the Problem)
머신러닝 프로젝트를 시작할 때 해결해야하는 비즈니스 문제를 명확하게 먼저 정의
2) 머신러닝 문제로 전환
머신러닝의 종류
(1) Supervised Learning (지도학습) : (목표) 예측
나에게 input data (feature) 가 있고, output (target)이 있어서, 이를 가지고 예측모델을 만드는 것
선생님이 학생을 가르치듯이 문제에 대한 정답을 가지고, 나온 결과를 계속하여 정답과 대조하여 풀어나가는 과정
output을 만드는것 = labeling 작업이 매우 중요하다. 일관성있는 레이블링이 필요
-Classification (범주 예측) : 분류, 인풋과 아웃풋을 가지고 함수식을 유추
-Regression (숫자 예측) : 회귀, 인풋과 아웃풋을 가지고 함수식을 유추
(2) Unsupervised Learning (비지도학습) : (목표) 데이터분석
나에게는 input data (feature)만 존재한다.
대부분의 비지도학습은 기존의 데이터를 그룹핑하고 해석하는데 목표를 두고있다.
- Clustering : 유사한 그룹끼리 군집화
[실제 현실에 적용시]
| Business Problem | Target/Output | ML Problem |
| 고객이 서비스를 이탈할 것인가? | 범주 : 이탈여부 (0/1) | Classification |
| 내년도 서비스 예상 매출액은 얼마인가? | 숫자 : 매출액 | Regression |
| 사용자 정보오 구매이력 기반 고객 세분화 | Clustering |
(3) 머신러닝 도입 가능성/필요성 검토
(4) 효과검증 설계
머신러닝 도입에 따른 효과 검증 프레임워크
문제정의 -> 가설설정 -> 해결방안 -> 효과검증
[효과검증 설계 예시]
"보통 게임에서 재방문율이라는 지표가 중요하다."
①문제정의 : 사용자의 서비스 재방문율(Retention)을 높이고 싶다.
②가설설정 : 사용자가 서비스를 이탈할 것 같은 시점에 프로모션/혜택을 제공하여 재방문하게 한다.
③해결방안 : 서비스 이탈 예측 모델을 개발한다.
④효과검증 : 사용자의 재방문율(Retention)이 증가했는지 확인한다.
-------------------------------------------------------------
2. 데이터준비
Data Preprocessing & Feature Engineering
--------------------------------------------------------------
3. 모델구축 & 평가
Build Model & Evaluation
머신러닝 문제로 전환하고 데이터 준비를 마친 이후에는 적절한 머신러닝 모델 & 알고리즘을 선택하여 모델을 구축하고 평가
[세부프로세스]
모델 & 알고리즘 선택 - 실무적 제약사항을 고려한 적합모델 선택 - 하이퍼파라미터 설정 - 모델학습 - 모델평가
1) 모델 & 알고리즘 선택
각 모델별로 어떤 알고리즘을 사용할 수 있는지, 그 알고리즘에 따른 결과는 어떤 값인지 알 수 있다.
| ML Model | Algorithm | Result |
| Classification (분류) | Logistic Regression Decision Tree Support Vector Machine |
범주예측 (0/1) |
| Regression (회귀) | Linear Regression Ridge Regression Lasso Regression |
숫자 예측 |
| Clustering (군집화) | K-means DBscan |
군집 |
2) 머신러닝 관점 모델 평가
Regression(회귀)는 실제값(y)과 예측값(y^)의 차이=오차(Loss/Cost/Error)를 통해 모델의 성능을 평가한다.
Classification(분류)는 실제 범주와 예측한 범주의 일치하는 정도를 통해 모델의 성능을 평가한다.
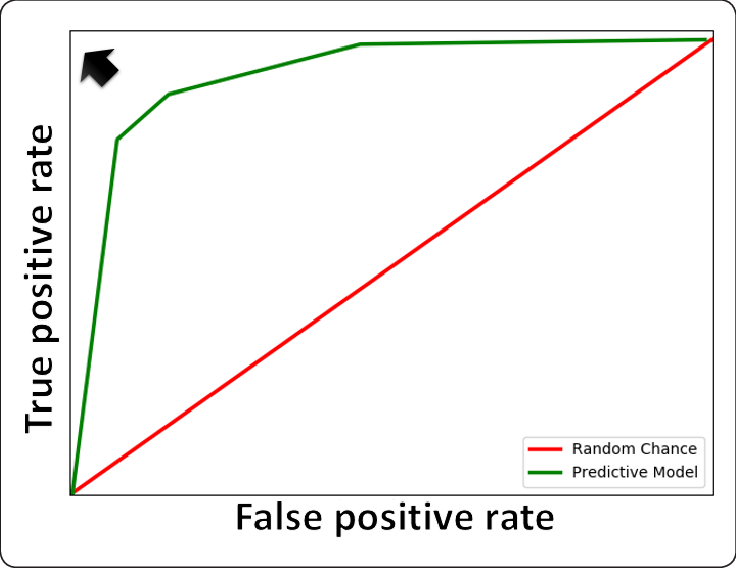
(평가 지표 : 정확도/조화평균/혼동행렬/AUC/ROC Curve 등)
3) 비즈니스관점 모델 평가
경우에 따라서는 모데 도입을 통해 기대되는 손익이 더 중요할 수 있음
기대손익(Expected Value)은 어떤 이벤트가 발생할 확률 P(x)과 그로 인해 발생하는 손익 V를 계산하여 평가
Expected Value = P(x1) * V1 + P(x2) * V2 + ...
기대손익을 구하기 위한 몇가지 추가적인 개념
1) 혼동행렬 (Confusion Matrix)
분류모델(Classification)의 성능을 평가할 때 사용하는 지표
각 경우의 수를 넣는다

2) 확률행렬 (Matrix of Probabilities)
혼동행렬 값을 확률로 정규화 한 행렬
3) 확률행렬과 비용편익 분석을 통한 모델 평가
확률행렬 * 비용손익행렬
4) ROC Curve : 왼쪽 위쪽으로 굽을 수록 정확도가 높다.
5) AUC : ROC 곡선 아래쪽의 넓이가 넓을 수록 정확도가 높다.
'AI' 카테고리의 다른 글
| [Tensorflow 자격증 공부] 선형함수와 오차 (0) | 2022.01.06 |
|---|---|
| [Tensorflow 자격증 공부] 스케일링/원핫인코딩/relu/loss함수/compile/체크포인트 (0) | 2022.01.05 |
| [Tensorflow 자격증 공부] Fully Connected Layer (Dense Layer) (0) | 2022.01.04 |
| [AI] 머신러닝을 위한 데이터 준비 (0) | 2022.01.04 |
| [AI] 머신러닝의 개념과 요소 (0) | 2022.01.04 |

