크롤링이란?
웹페이지에 있는 정보를 내가 원하는 것만 뽑아서 수집하는 것이다.
주로 크롤링으로 많이 하는 것들은 이미지 파일들이다.
이번에는 파이썬을 사용하여 이미지를 크롤링하고, 크롤링한 이미지 파일들을 opencv를 이용해서 원하는 포맷으로 편집까지 해보려한다.
크롤링에 많이 사용하는 것들은 뷰티풀숲(Beautiful Soup) 이다.
하지만 정적인 콘텐츠가 아니고, 동적인 콘텐츠의 경우 실제로 웹 창이 열려야 이미지 소스들이 그제서야(?) 웹페이지에 다운이 되는 경우가 많이 있다.
그래서 셀레니움(Selenium)을 사용한다.
1. 필요한 모듈을 설치한다.
!pip install bs4
!pip install selenium
!pip install opencv-python2. 필요한 모듈을 import 한다
from bs4 import BeautifulSoup
from selenium import webdriver
import requests
import urllib.request
import time
import os
import urllib
from PIL import Image
import cv2
3. 자동차의 이미지를 크롤링 할 예정이므로 cars라는 딕셔너리에 '검색어':'저장할폴더이름' 형식으로 key값과 value값을 정한다.
link라는 빈 리스트를 만든다. 이 리스트는 나중에 img 소스의 링크를 저장할 리스트이다.
cars = {'셀토스':'seltos2'}
link = []
4. 먼저 셀레니움으로 웹드라이버를 불러온다.
크롬 웹드라이버를 사용했는데, 크롬웹드라이버를 본인의 크롬 버전에 맞게 exe 파일을 다운받아서 exe 드라이버가 다운받아져 있는 디렉토리 경로를 입력하면 된다.
처음으로 띄울 웹페이지의 url을 입력한다.
for key in cars:
driver = webdriver.Chrome('D:\chromedriver_win32\chromedriver.exe')
driver.get('https://naver.com')
5. 네이버 창의 우클릭을 하여 "검사" 를 클릭한다.
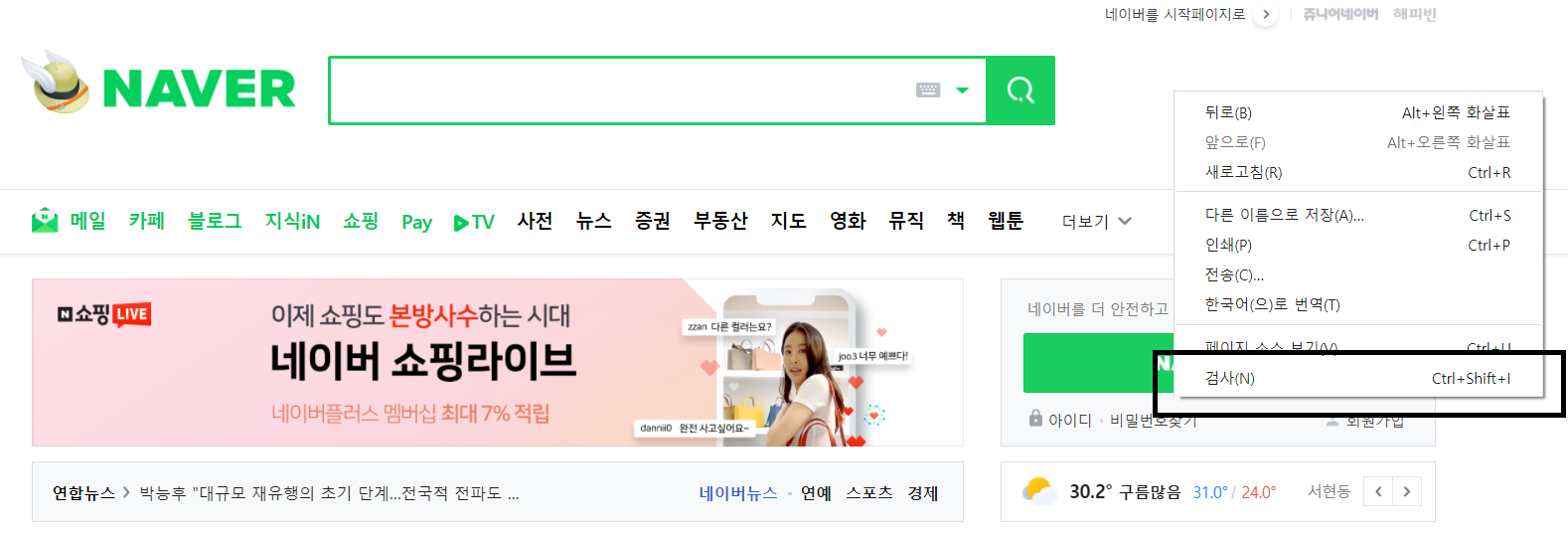
6. '검사' 클릭시 나오는 우측 창 상단에 '화살표'모양을 누르고 검색창에 가져다 대면 해당 검색창 소스의 이름을 알 수 있다. name = 'query' 라고 적혀있다. 이 이름을 알아 내야 한다.

7. 알아낸 이름을 driver.find_element_by_name() 안에 작성한다.
이 함수는 말 그대로 요소의 이름으로 찾기 라는 것이다. 검색창이 소스상에서 이름이 query이므로 검색창에 .send_keys라는 매소드로 초기에 설정한 cars의 key 값인 '셀토스'를 입력한다.
입력 후 검색 버튼을 눌러야하는데, 이를 실행하는 방법은 다음과 같다.
검색버튼을 동일하게 화살표 모양으로 눌러서 html 소스를 찾는다.
해당 소스위에서 우클릭을 한 후 'copy' -> 'Copy XPath'를 한 후 driver.find_element_by_xpath() 안에 붙여넣기를 한다.
이는 해당 요소를 xpath로 찾는 다는 뜻이다. 이후 .click이라는 메소드를 하용하여 검색버튼을 클릭하는 행위까지 추가한다.

driver.find_element_by_name('query').send_keys(key)
driver.find_element_by_xpath('//*[@id="search_btn"]').click()
8. 여기서 조금 삽질? 까다로운 것이 나온다. 자동차 명에 따라서 어떤거는 상단에 바로 네이버 자동차 검색 페이지로 연결되는 것이 나오지만, 지금의 경우처럼 상단에 광고 링크나 파워링크가 먼저 떠서 네이버자동차검색 페이지 연결 링크가 아래로 내려가는 경우가 있다.
이는 어쩔 수 없지만 케이스에 따라 xpath를 바꿔주어야 한다.

대부분 맨 위의 상단의 div[2]값을 가져오는 듯 하지만, div[3] 값을 가져와야하는 경우도 있다.
driver.find_element_by_xpath('//*[@id="main_pack"]/div[2]/div/div[2]/div/div[1]/dl/dt[1]/a').click()
# driver.find_element_by_xpath('//*[@id="main_pack"]/div[3]/div/div[2]/div/div[1]/dl/dt[1]/a').click()
9. 네이버 자동차 검색 링크를 클릭하면, 새로운 탭이 생성되므로 driver.swith_to.window로 탭을 변경해주어야 한다.
네이버 자동차 검색 링크에서 이미지 탭으로 이동한 후 time.sleep(1)로 1초 정도 이미지가 다운될 시간을 준다.(이는 생략 가능하지만, 생략할 경우 이미지가 다운 되기 전에 이미지 소스를 가져오려고 하여 도중에 에러가 나는 경우가 발생 할 수도 있다.)
img 라는 변수에 img 태그를 담고 get_attribute로 소스만 가져온다. 즉 해당 이미지가 가지고있는 인터넷 상에서 주소(url)만을 가져온다.
그 url을 초기에 만들어둔 빈 리스트인 link에 담는다.

driver.switch_to.window(driver.window_handles[1])
driver.find_element_by_xpath('//*[@id="content"]/div[1]/ul/li[3]/a').click()
time.sleep(1)
img = driver.find_element_by_xpath('//*[@id="container"]/div[5]/div/div/ul/li[2]/img')
img.get_attribute('src')
link.append(img.get_attribute('src'))
10. 최초 이미지는 위의 코드에서 저장을 했고, 그 이후에 더 많은 이미지를 진행하고 싶다면 for문으로 한장씩 옆으로 넘기면서 img 소스를 link라는 리스트에 저장을 하면 된다.
for i in range(19):
driver.find_element_by_xpath('//*[@id="container"]/div[5]/div/a[2]/div').click()
time.sleep(1)
img = driver.find_element_by_xpath('//*[@id="container"]/div[5]/div/div/ul/li[2]/img')
img.get_attribute('src')
link.append(img.get_attribute('src'))
11. 드라이버를 닫고, os 모듈을 통해 폴더를 생성한다. 초기에 지정한 cars[key] 의 value값으로 폴더를 만든다.
count 값은 폴더 안에서 이름을 지정할 때 중복이 되지 않게 하기위해 count를 하나씩 증하했다.
area = (0,0,980,570) 으로 지정하여 image를 원하는 크기로 자른 후 저장한다.
driver.close()
count = 0
os.makedirs(os.path.join('D:/blog/'+cars[key]))
for url in link:
count += 1
urllib.request.urlretrieve(url, 'D:/blog/'+cars[key]+'/asigd'+str(count)+'iwjed.jpg')
image = Image.open('D:/blog/'+cars[key]+'/asigd'+str(count)+'iwjed.jpg')
area = (0,0,980,570)
crop_image = image.crop(area)
crop_image.save('D:/blog/'+cars[key]+'/asigd'+str(count)+'iwjed.jpg')
12. 저장한 이미지를 2개씩 붙이고 border(테두리)를 만들어주는 코드이다.
for i in range(1,22, 2):
img1 = cv2.imread('D:/blog/'+cars[key]+'/asigd'+str(i)+'iwjed.jpg')
img2 = cv2.imread('D:/blog/'+cars[key]+'/asigd'+str(1+i)+'iwjed.jpg')
addv = cv2.vconcat([img1, img2])
bordersize = 2
border = cv2.copyMakeBorder(addv, top=bordersize, bottom=bordersize, left=bordersize, right=bordersize, borderType=cv2.BORDER_CONSTANT, value=[0,0,0])
cv2.imwrite('D:/blog/'+cars[key]+'/asigd'+str(i*123)+'iwjed.jpg', border)
전체 코드 참조
cars = {'셀토스':'seltos2'}
link = []
for key in cars:
driver = webdriver.Chrome('D:\chromedriver_win32\chromedriver.exe')
driver.get('https://naver.com')
driver.find_element_by_name('query').send_keys(key)
driver.find_element_by_xpath('//*[@id="search_btn"]').click()
driver.find_element_by_xpath('//*[@id="main_pack"]/div[2]/div/div[2]/div/div[1]/dl/dt[1]/a').click()
# driver.find_element_by_xpath('//*[@id="main_pack"]/div[3]/div/div[2]/div/div[1]/dl/dt[1]/a').click()
# driver.find_element_by_xpath('//*[@id="main_pack"]/div[2]/div/div[2]/div/div[1]/dl/dt[1]/a').click()
driver.switch_to.window(driver.window_handles[1])
driver.find_element_by_xpath('//*[@id="content"]/div[1]/ul/li[3]/a').click()
time.sleep(1)
img = driver.find_element_by_xpath('//*[@id="container"]/div[5]/div/div/ul/li[2]/img')
img.get_attribute('src')
link.append(img.get_attribute('src'))
for i in range(19):
driver.find_element_by_xpath('//*[@id="container"]/div[5]/div/a[2]/div').click()
time.sleep(1)
img = driver.find_element_by_xpath('//*[@id="container"]/div[5]/div/div/ul/li[2]/img')
img.get_attribute('src')
link.append(img.get_attribute('src'))
# driver.find_element_by_xpath('//*[@id="container"]/div[5]/div/a[2]/div').click()
driver.close()
count = 0
os.makedirs(os.path.join('D:/blog/'+cars[key]))
for url in link:
count += 1
urllib.request.urlretrieve(url, 'D:/blog/'+cars[key]+'/asigd'+str(count)+'iwjed.jpg')
image = Image.open('D:/blog/'+cars[key]+'/asigd'+str(count)+'iwjed.jpg')
area = (0,0,980,570)
crop_image = image.crop(area)
crop_image.save('D:/blog/'+cars[key]+'/asigd'+str(count)+'iwjed.jpg')
for i in range(1,22, 2):
img1 = cv2.imread('D:/blog/'+cars[key]+'/asigd'+str(i)+'iwjed.jpg')
img2 = cv2.imread('D:/blog/'+cars[key]+'/asigd'+str(1+i)+'iwjed.jpg')
addv = cv2.vconcat([img1, img2])
bordersize = 2
border = cv2.copyMakeBorder(addv, top=bordersize, bottom=bordersize, left=bordersize, right=bordersize, borderType=cv2.BORDER_CONSTANT, value=[0,0,0])
cv2.imwrite('D:/blog/'+cars[key]+'/asigd'+str(i*123)+'iwjed.jpg', border)


